
{kind=link}
Editor’s observe: This publish is a part of the AI Decoded sequence, which demystifies AI by making the know-how extra accessible, and which showcases new {hardware}, software program, instruments and accelerations for RTX PC customers.
As generative AI advances and turns into widespread throughout industries, the significance of operating generative AI purposes on native PCs and workstations grows. Native inference provides customers lowered latency, eliminates their dependency on the community and allows extra management over their information.
NVIDIA GeForce and NVIDIA RTX GPUs characteristic Tensor Cores, devoted AI {hardware} accelerators that present the horsepower to run generative AI regionally.
Steady Video Diffusion is now optimized for the NVIDIA TensorRT software program growth package, which unlocks the highest-performance generative AI on the greater than 100 million Home windows PCs and workstations powered by RTX GPUs.
Now, the TensorRT extension for the favored Steady Diffusion WebUI by Automatic1111 is including help for ControlNets, instruments that give customers extra management to refine generative outputs by including different pictures as steering.
TensorRT acceleration will be put to the check within the new UL Procyon AI Picture Era benchmark, which inner checks have proven precisely replicates real-world efficiency. It delivered speedups of fifty% on a GeForce RTX 4080 SUPER GPU in contrast with the quickest non-TensorRT implementation.
Extra Environment friendly and Exact AI
TensorRT allows builders to entry the {hardware} that gives totally optimized AI experiences. AI efficiency sometimes doubles in contrast with operating the appliance on different frameworks.
It additionally accelerates the most well-liked generative AI fashions, like Steady Diffusion and SDXL. Steady Video Diffusion, Stability AI’s image-to-video generative AI mannequin, experiences a 40% speedup with TensorRT.
The optimized Steady Video Diffusion 1.1 Picture-to-Video mannequin will be downloaded on Hugging Face.
Plus, the TensorRT extension for Steady Diffusion WebUI boosts efficiency by as much as 2x — considerably streamlining Steady Diffusion workflows.
With the extension’s newest replace, TensorRT optimizations lengthen to ControlNets — a set of AI fashions that assist information a diffusion mannequin’s output by including additional situations. With TensorRT, ControlNets are 40% quicker.
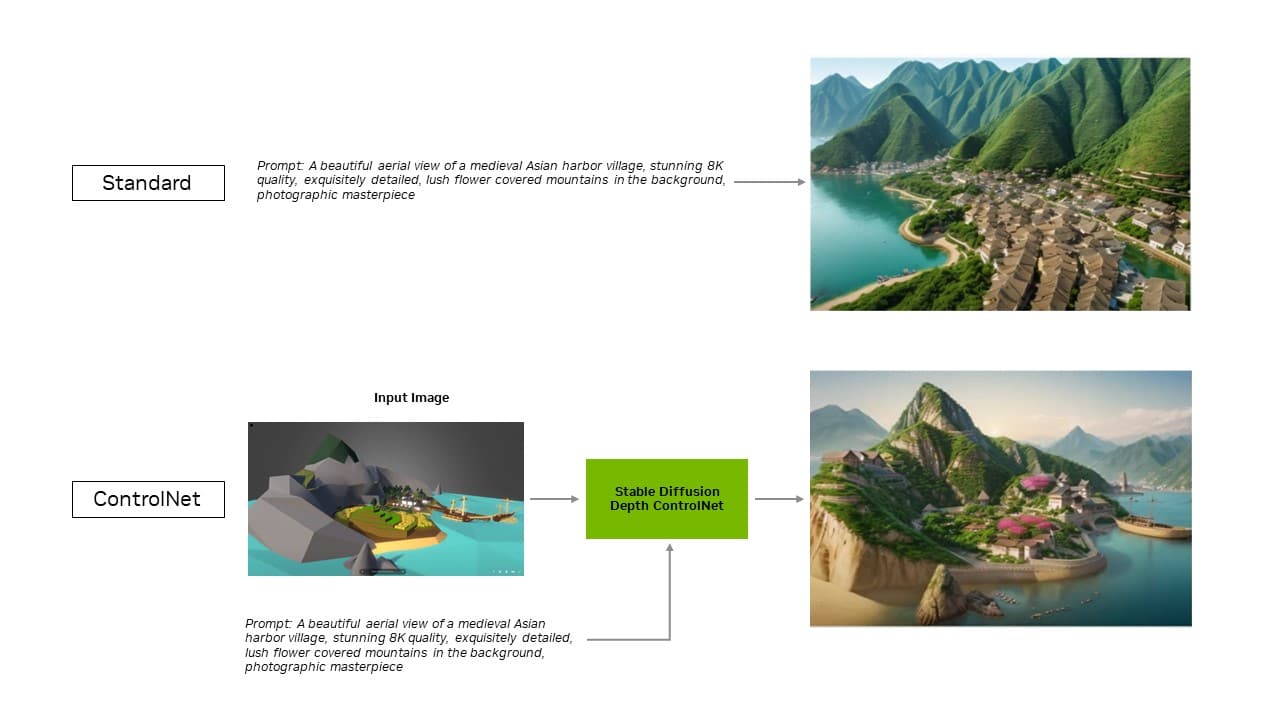
Customers can information elements of the output to match an enter picture, which provides them extra management over the ultimate picture. They’ll additionally use a number of ControlNets collectively for even better management. A ControlNet is usually a depth map, edge map, regular map or keypoint detection mannequin, amongst others.
Obtain the TensorRT extension for Steady Diffusion Net UI on GitHub in the present day.
Different Widespread Apps Accelerated by TensorRT
Blackmagic Design adopted NVIDIA TensorRT acceleration in replace 18.6 of DaVinci Resolve. Its AI instruments, like Magic Masks, Pace Warp and Tremendous Scale, run greater than 50% quicker and as much as 2.3x quicker on RTX GPUs in contrast with Macs.
As well as, with TensorRT integration, Topaz Labs noticed an as much as 60% efficiency enhance in its Photograph AI and Video AI apps — corresponding to picture denoising, sharpening, picture tremendous decision, video sluggish movement, video tremendous decision, video stabilization and extra — all operating on RTX.
Combining Tensor Cores with TensorRT software program brings unmatched generative AI efficiency to native PCs and workstations. And by operating regionally, a number of benefits are unlocked:
- Efficiency: Customers expertise decrease latency, since latency turns into impartial of community high quality when the complete mannequin runs regionally. This may be essential for real-time use instances corresponding to gaming or video conferencing. NVIDIA RTX affords the quickest AI accelerators, scaling to greater than 1,300 AI trillion operations per second, or TOPS.
- Value: Customers don’t should pay for cloud companies, cloud-hosted software programming interfaces or infrastructure prices for big language mannequin inference.
- All the time on: Customers can entry LLM capabilities anyplace they go, with out counting on high-bandwidth community connectivity.
- Information privateness: Non-public and proprietary information can at all times keep on the person’s system.
Optimized for LLMs
What TensorRT brings to deep studying, NVIDIA TensorRT-LLM brings to the newest LLMs.
TensorRT-LLM, an open-source library that accelerates and optimizes LLM inference, contains out-of-the-box help for well-liked group fashions, together with Phi-2, Llama2, Gemma, Mistral and Code Llama. Anybody — from builders and creators to enterprise workers and informal customers — can experiment with TensorRT-LLM-optimized fashions within the NVIDIA AI Basis fashions. Plus, with the NVIDIA ChatRTX tech demo, customers can see the efficiency of varied fashions operating regionally on a Home windows PC. ChatRTX is constructed on TensorRT-LLM for optimized efficiency on RTX GPUs.
NVIDIA is collaborating with the open-source group to develop native TensorRT-LLM connectors to well-liked software frameworks, together with LlamaIndex and LangChain.
These improvements make it straightforward for builders to make use of TensorRT-LLM with their purposes and expertise the most effective LLM efficiency with RTX.
Get weekly updates immediately in your inbox by subscribing to the AI Decoded e-newsletter.